[Video] Ứng dụng ‘Chat With RTX’: chatbot hoạt động nhờ vào card đồ họa NVIDIA RTX AI
Phiên bản demo Chat With RTX dành cho bất kỳ khách hàng nào sở hữu bộ xử lý đồ họa (GPU) (1) RTX đều có thể sử dụng chatbot (2) GPT được cá nhân hóa.
(1) GPU (Graphics Processing Unit): được gọi là bộ xử lý đồ họa. Là một vi mạch chuyên dụng được thiết kế để thao tác và truy cập bộ nhớ đồ họa một cách nhanh chóng, đẩy nhanh việc tạo ra các hình ảnh trong bộ đệm khung hình trước khi xuất ra màn hình hiển thị.
(2) Chatbot: là một chương trình trí tuệ nhân tạo, được thiết kế nhằm mô phỏng lại các cuộc trò chuyện với khách hàng thông qua nền tảng internet. Chatbot công nghệ trí tuệ nhân tạo (AI) và xử lý ngôn ngữ (NLP) để hiểu các câu hỏi và tự động trả lời.
Các ứng dụng chatbot được hàng triệu người trên thế giới sử dụng mỗi ngày, được hỗ trợ bởi các máy chủ đám mây dựa trên GPU NVIDIA. Giờ đây, những công cụ đột phá này sắp có mặt trên máy tính để bàn (PC) hệ điều hành Windows được hỗ trợ bởi card đồ họa NVIDIA RTX AI nhanh chóng và cục bộ.
Hiện tại, khách hàng có thể tải ứng dụng Chat With RTX và dùng thử, đây là bản demo công nghệ cho phép khách hàng cá nhân hóa chatbot bằng nội dung của riêng họ, được tăng tốc bằng GPU NVIDIA GeForce RTX Series 30 cục bộ trở lên với bộ nhớ truy cập ngẫu nhiên video – VRAM (Video Random Access Memory) ít nhất 8GB.
Có thể hỏi chatbot bất cứ điều gì
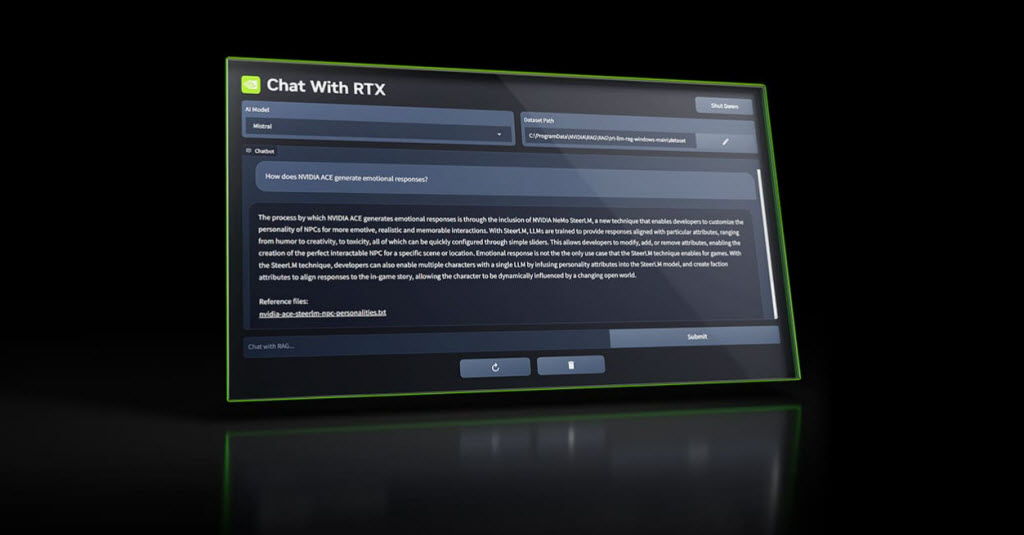
Ứng dụng Chat With RTX sử dụng thế hệ tăng cường truy xuất (RAG) (3), phần mềm NVIDIA TensorRT-LLM (4) và khả năng tăng tốc của công nghệ RTX (5) để mang lại khả năng AI tạo sinh cho các PC Windows cục bộ được hỗ trợ bởi card đồ họa GeForce. khách hàng có thể nhanh chóng, dễ dàng kết nối các tệp cục bộ trên máy tính để bàn dưới dạng tập dữ liệu với mô hình ngôn ngữ lớn nguồn mở như Mistral hoặc Llama 2, cho phép truy vấn để có câu trả lời nhanh chóng, phù hợp với ngữ cảnh.
(3) Tạo tăng cường truy xuất (RAG – retrieval-augmented generation): là một kỹ thuật nhằm nâng cao độ chính xác và độ tin cậy của các mô hình AI tạo sinh với các dữ kiện được lấy từ các nguồn bên ngoài.
(4) TensorRT-LLM: là thư viện mã nguồn mở giúp tăng tốc và tối ưu hóa hiệu suất suy luận của các mô hình ngôn ngữ lớn (LLM) mới nhất trên nền tảng NVIDIA AI.
(5) RTX là viết tắt của cụm từ Ray Tracing Texel eXtreme dịch sang tiếng Việt thì có nghĩa là card được tích hợp công nghệ dò tia (Ray Tracing).
Thay vì tìm kiếm qua các ghi chú hoặc nội dung đã lưu, khách hàng chỉ cần gõ truy vấn. Ví dụ, một người có thể hỏi: “Đối tác của tôi đã giới thiệu nhà hàng nào khi ở Las Vegas?” và Chat With RTX sẽ quét các tệp cục bộ mà khách hàng trỏ tới và đưa ra câu trả lời kèm theo ngữ cảnh.
Công cụ chatbot này hỗ trợ nhiều định dạng tệp tin khác nhau, bao gồm .txt, .pdf, .doc/.docx và .xml. Trỏ ứng dụng vào thư mục chứa các tệp này và chatbot sẽ tải chúng vào thư viện của nó chỉ sau vài giây.
Khách hàng cũng có thể dùng dữ liệu từ video và danh sách phát trên nền tảng YouTube. Việc thêm địa chỉ URL của video vào Chat With RTX cho phép khách hàng tích hợp kiến thức này vào chatbot của họ để trả lời các truy vấn theo ngữ cảnh. Ví dụ: yêu cầu đề xuất du lịch dựa trên nội dung từ các video có liên quan được yêu thích hoặc nhận hướng dẫn nhanh và cách thực hiện dựa trên các thông tin giáo dục hàng đầu.
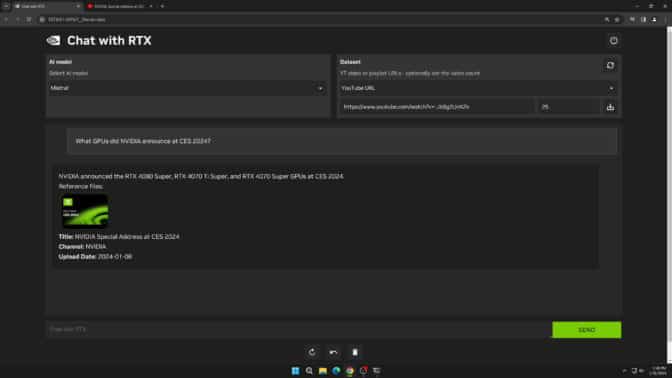 Chat With RTX có thể tích hợp kiến thức video từ nền tảng YouTube vào các truy vấn.
Chat With RTX có thể tích hợp kiến thức video từ nền tảng YouTube vào các truy vấn.
Vì Chat With RTX chạy cục bộ trên máy tính và máy trạm chạy Windows RTX vì vậy kết quả được cung cấp rất nhanh và dữ liệu của khách hàng vẫn được lưu trên thiết bị. Thay vì dựa vào các dịch vụ LLM dựa trên đám mây, Chat with RTX cho phép khách hàng xử lý dữ liệu nhạy cảm trên PC cục bộ mà không cần chia sẻ dữ liệu đó với bên thứ ba hoặc có kết nối Internet.
Để sử dụng Chat with RTX, khách hàng cần có: card đồ họa GeForce RTX Series 30 trở lên với VRAM tối thiểu 8GB, hệ điều hành Windows 10 hoặc 11 và trình điều khiển GPU NVIDIA mới nhất.
Phát triển ứng dụng dựa trên mô hình ngôn ngữ lớn (LLM) với công nghệ dò tia (RTX)
Chat With RTX cho thấy tiềm năng tăng tốc LLM bằng GPU RTX. Ứng dụng này được xây dựng từ dự án tham khảo dành cho nhà phát triển thư viện mã nguồn mở TensorRT-LLM RAG, có sẵn trên nền tảng GitHub. Các nhà đầu tư có thể sử dụng các dự án tham khảo để phát triển và triển khai các ứng dụng dựa trên tăng cường truy xuất của riêng họ cho công nghệ dò tia, được tăng tốc bởi TensorRT-LLM.
Xem thêm thông tin chi tiết về ứng dụng tại Chat With RTX
Để xem các tin bài khác về “Chatbot”, hãy nhấn vào đây.
![]()
Nguồn: NVIDIA